
Have you ever felt that a team after jumping to an early lead or even blowing out their opponent, they start playing worse? If yes, you are not alone, and also it turns out that this is not some sort of cognitive illusion of your mind, but rather it is a robust phenomenon. Jeremias Englemann was the first – to the best of my knowledge – to show that there are (linear) leading effects in the NBA, that is, the team in the lead plays approximately 0.35pts/100 possessions worse for every point of lead. I then thought let’s explore this for the NFL and while we are at it let’s talk a bit about mixed effects models.
A linear mixed effects model takes the following form: 






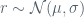
The fixed effects essentially define the slope of the line (with respect to each variable), while the random effects define a different intercept for each “sub population”. These different intercepts can be though of us draws from a random variable (thus the name “random effects”). In our case we have two fixed effects, i.e., the score differential at the beginning of the drive and the field position at the beginning of the drive (distance from goal line). We also have random effects for the team with possession and the team in defense. So you can imagine that these random effects capture the (constant) offensive and defensive ability of each team (points scored per drive), while the fixed effects capture the relationship between score differential and field position with the points scored per drive. Other settings are possible too but we do not use them here. For example, if we believe that different teams will be impacted differently by the point differential or the starting field position, we can have random slopes as well, where the slopes will now be different for different groups/populations (in our case teams). Nevertheless in our analysis we only use fixed effects and random intercepts.
We used play-by-play data since 2000 and estimated the mixed effects models on a 10-year rolling window (you can find the code here). From the analysis, we removed drives that were not complete prior to the end of the half/game. Overall, during the past 10 years teams play 0.1 pts/10 drives worse for every point they lead. Furthermore, these leading effects are relatively stable (despite the slight decrease we see, the estimated confidence intervals overlap) over the period we examined with values ranging from -0.07 pts/10 drives to -0.1 pts/10 drives as we can see in the figure below.

Now if you have been following my analysis you might be wondering “wait did he just do what I think he did?” and you will be right. I used a linear model when I should have used a multinomial one, where the classes will be the outcome at the end of the drive. That would have been the absolute right thing to do but I went with the linear model simply because it is easier to interpret the coefficients. However, if you run a multinomial mixed effects model you will see that for classes that correspond to higher scores, their probability is higher with an increase in the score differential.
